


The prevalence of machine learning (ML) and artificial intelligence (AI) in solving complex problems has increased, leading to a demand for testing professionals to support data science and ML teams with their data, pipelines, models, services, and AI ethics.
This course focuses on the unique aspects of testing ML models compared to traditional programming. It uses Python, the most popular language for ML and AI, and starts by explaining the differences between ML and traditional programming.
Key topics include performing adversarial attacks to test model robustness, behavioral testing techniques, and ensuring fairness and responsibility in ML systems to prevent issues like bias. The course concludes by examining production-deployed models. Although it doesn’t cover every ML model type, it provides comprehensive knowledge and tools for effectively testing ML models in real-world applications.


ML and AI become important as companies look to solve problems that leverage data that traditional programming cannot.
Chapter1
Machine learning (ML) is a complex and expansive field with various types, techniques, and applications. These include regression, clustering, supervised and unsupervised learning, reinforcement learning, transfer learning, ensemble learning, and fields like Natural Language Processing (NLP) and Computer Vision. Instead of delving deeply into these areas, this text examines them from a tester’s perspective.
Testers don’t need in-depth knowledge of all ML details but should understand core AI concepts and the process of training ML models. This knowledge helps identify risks, potential biases, and areas needing scrutiny.
ML is often conflated with artificial intelligence (AI), but while ML falls under AI, it typically represents “Narrow AI” (or Weak AI), focusing on specific tasks rather than the human-like intelligence implied by “Strong AI.” Even narrow AI applications, like language translation and recommendation systems, are intelligent within their domains.
A key ML application is prediction, which involves identifying patterns in data to forecast future values. For example, predicting store sales based on previous transaction data involves recognizing relationships, such as the correlation between the number of people and spending.
Unlike traditional programming, which uses defined rules to process data and produce outputs, ML uses data and outputs to learn the rules or patterns. Key terminology includes:
- Features: Input data used for making predictions.
- Labels: Output data that the model aims to predict.
- Dataset: Collection of features and labels.
- Weights: Parameters that describe relationships in the data.
ML models are trained by analyzing and experimenting with data, leading to the identification of these weights. The process involves significant testing to ensure model accuracy and reliability. Understanding this process helps testers ensure that ML models are effective and unbiased.
The text concludes with the promise of further exploring model training, emphasizing the importance of testing throughout the ML development process.


Chapter2.1 – Building a Machine Learning Model
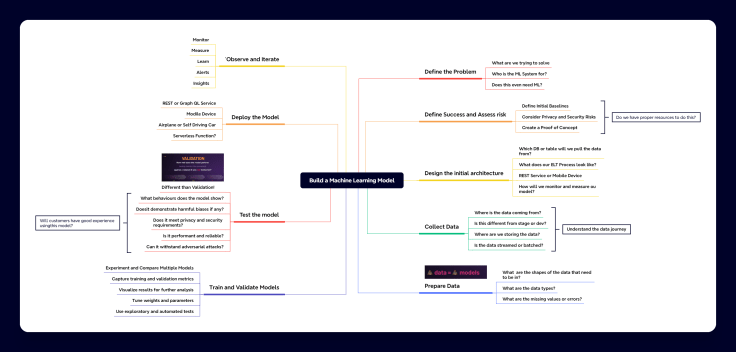
Steps for Building a Machine Learning Model
- Define the Problem:
- Determine what problem the ML system is solving.
- Identify the target users.
- Assess if ML is necessary for the solution.
- Establish Metrics:
- Define success and failure metrics beyond just solving the problem.
- Set initial baselines.
- Consider privacy and security risks.
- Develop a proof of concept to evaluate risks and dependencies.
- Ensure the team has the necessary expertise and resources.
- Design Initial Architecture:
- Plan the data sources and data pipeline.
- Decide if the model will be accessed via REST service, mobile device, etc.
- Plan for monitoring and measuring model performance.
- Data Collection:
- Identify data sources and storage solutions.
- Address storage and compute costs.
- Determine how data will be streamed or batched.
- Automate data collection into data pipelines.
- Data Preparation:
- Prepare data in the required format.
- Normalize and convert data types as needed.
- Address missing values and errors.
- Ensure data quality to avoid poor model performance.
- Model Training and Validation:
- Train and validate multiple models to find the best fit.
- Capture logs and metrics, visualize results.
- Tune model weights and parameters to improve performance.
- Continuously test and validate models to prevent overfitting.
- Testing the Models:
- Conduct continuous testing throughout all steps.
- Validate model performance using metrics like accuracy on unseen data.
- Assess model behaviors for biases.
- Ensure models meet privacy, security, performance, and reliability standards.
- Check for customer experience quality and resistance to adversarial attacks.
- Deployment:
- Deploy models to appropriate platforms (REST service, mobile device, etc.).
- Test integrations and functionality in the deployment environment.
- Observe and Iterate:
- Monitor and measure model performance post-deployment.
- Use insights and alerts to guide further training and improvements.
- Continuously iterate to refine and enhance the model.

For Chapter2.2 Refer to the collab exercise in the corse which is explained neatly.
Chapter3 – Where do testers fit in Machine Learning?
Machine learning (ML) systems are widely used in everyday applications, such as virtual assistants (Alexa, Google, Siri), image and video processing (camera filters, optimization), personalization (Netflix recommendations), and security (fraud prevention, spam detection). They are also increasingly applied in agriculture and medicine.
Despite their benefits, ML and AI systems are complex and challenging to design and implement, often requiring multiple models and extensive testing. An example of a failed ML application is Zillow’s house-flipping business. Initially, Zillow’s models performed well but eventually degraded, leading to overpricing properties and significant financial losses. The failure highlighted several lessons:
- Suspect data quality, with publicly shared data being easily manipulated.
- Flawed system design, relying entirely on automated models without human oversight.
- Introduction of biases, focusing solely on prices without considering buyer perspectives.
- External risks, such as COVID-19, affecting the housing market and leading to increased renovation costs.
This example underscores the importance of continuous testing, measuring, and iterating, concepts central to MLOps. MLOps combines ML with DevOps practices to reliably and efficiently deploy and maintain ML models in production. It involves phases like data collection, preparation, model training, testing, deployment, and observation, all requiring thorough testing.
High-quality MLOps necessitates robust testing throughout every phase of the ML lifecycle.


Chapter4 – Adversarial Attacks
Ensuring AI quality involves focusing on reliability, robustness, security, privacy, and safety. Machine learning (ML) models have weaknesses that adversarial attacks can exploit. These attacks reveal vulnerabilities that might lead to significant issues, such as misclassifying objects or causing dangerous behaviors in critical systems like self-driving cars.
Adversarial attacks involve techniques to trick ML models, such as adding noise to images or altering their appearance slightly, which can cause the model to make incorrect predictions. For example, a self-driving car might misread a stop sign as a speed limit sign with just a few added stickers, or a security system might fail to detect a human if they wear specific patterns.
To defend against these attacks, data scientists and ML engineers must test for and mitigate such vulnerabilities. This involves threat modeling, which identifies potential attack vectors and devises ways to protect against them. Attacks can occur during the model’s training or use and can be either black box (no access to model parameters) or white box (full access to model parameters).
In practice, creating adversarial attacks can be straightforward. Using tools like PyTorch, one can build and test models, applying various attack techniques to evaluate their robustness. For example, by adding noise to an image of a hummingbird, the model might incorrectly classify it as a bubble. Similarly, inverting the colors of an image (semantic attack) can lead to misclassification, as seen with a dalmatian being identified as an impala.
These tests are crucial for improving model robustness and ensuring that they perform reliably in real-world scenarios. Testers can contribute significantly by designing and executing such attacks, thus playing a vital role in maintaining the security and reliability of ML systems


Chapter 5.1 – Behaviour Testing and Training the NLP Model
The goal is to demonstrate behavioral testing techniques using a Natural Language Processing (NLP) model, based on concepts from the 2020 “Beyond Accuracy” paper by Marco Tulio Ribeiro et al. This paper emphasizes testing various model behaviors and capabilities beyond mere accuracy and loss metrics. Defining and testing desired behaviors throughout the modeling process results in better-performing models and a more accurate picture of model performance.
The paper highlights that teams using these methods created twice as many tests and found almost three times as many bugs. One example involved defining linguistic capabilities like vocabulary, named entity recognition, and negation, then creating test cases to evaluate the model’s performance against these capabilities.
Types of behavioral testing include Minimum Functionality Tests (MFT), Invariance Tests (INV), and Directional Expectation Tests (DET). These tests help compare different model iterations and measure failure rates across various models, such as those from Microsoft, Google, Amazon, and open-source models like BERT and RoBERTa.
In a practical demonstration, a Colab Notebook is used to explore an NLP model for sentiment analysis on IMDB movie reviews. This process involves:
- Setting Up: Changing the runtime to a GPU and loading necessary functions.
- Collecting Data: Using pre-organized IMDB reviews and splitting them into training and validation sets.
- Data Preprocessing: Tokenizing the text data, with a vocabulary size of 1000 words, removing punctuation, and handling unknown tokens with an “UNK” placeholder.
- Model Training: Training an LSTM model over several epochs, resulting in an accuracy improvement from 57% to 85% and validation accuracy around 80%.
- Evaluating: Assessing the model’s performance on the validation dataset, plotting accuracy and loss over epochs to visualize improvements and areas for further enhancement.
Behavioral testing, inspired by traditional software testing practices, is crucial for ensuring robust ML models by identifying and mitigating vulnerabilities throughout the development process.


Chapter 5.2 Test the model
Testing process and types of behavioral tests conducted on an NLP model for sentiment analysis:
- Example Review Testing:
- The model is tested with unseen example reviews such as “movie good” and “movie bad”.
- Predictions indicate “movie good” is positive (42%) and “movie bad” is negative (76%).
- Behavioral Testing:
- Tests are specified for different behaviors, attributes, and capabilities.
- Examples include sentences with mixed sentiments, neutral sentences, and sentences with subtle sentiments.
- Observations and questions arise from these tests, such as the need for a neutral sentiment class.
- Testing Frameworks:
- Different types of behavioral testing are introduced:
- Minimum Functionality Tests (MFT): Ensures basic functionality and correctness.
- Invariance Tests (INV): Verifies that predictions remain unchanged with minor alterations (e.g., typos or synonyms).
- Directional Expectation Tests (DIR/DET): Checks that sentiment changes as expected with added positive or negative words.
- Tests are automated using frameworks like pytest to verify model performance across different scenarios.
- Different types of behavioral testing are introduced:
- Automated Testing:
- Automated tests compare new model iterations against established baselines to ensure consistency.
- Example pytest functions demonstrate how to set up and run these tests, focusing on functionality and invariance.
- Exploratory Testing:
- Users are encouraged to experiment with different inputs and observe model behavior.
- The Colab Notebook allows for further exploration, such as training models with additional layers and testing for edge cases.
- Next Steps:
- The following video will cover AI fairness, using similar testing techniques to assess and ensure fairness in AI models.


Chapter6 Fair and Responsible AI
Biases in machine learning (ML) models and how to address them:
- Dependence on Data:
- ML models are dependent on the data they are trained and evaluated on. If there is a bias in the data, the model will learn and amplify it.
- Types of Biases:
- Historical Bias: Arises from flawed states of the world where the data was generated. For example, outdated hiring practices.
- Representation Bias: Occurs when training data sets poorly represent the people the model will serve, such as data from smartphone apps underrepresenting older adults.
- Measurement Bias: Happens when the accuracy of data varies across groups. For instance, healthcare costs used as a proxy for risk may not account for racial disparities in access to care.
- Aggregation Bias: When models perform well for the majority group but not for all groups. For example, ignoring ethnic differences in health conditions.
- Evaluation Bias: When benchmark data does not represent the target population. For example, facial analysis models perform poorly on people of color due to biased benchmarks.
- Deployment Bias: When models are used differently than intended. For example, risk assessment tools used inappropriately by judges in sentencing.
- Identifying and Addressing Biases:
- Biases can occur at any stage of the ML workflow: data collection, preparation, training, evaluation, and deployment.
- Google and other resources provide guidelines for designing and testing for fairness, diversity, and inclusivity.
- Fairness by Data:
- Ensure training and evaluation datasets are diverse and inclusive. Identify and address blind spots and biases in data.
- Monitor data drift over time to avoid historical biases.
- Fairness by Measurement and Modeling:
- Balanced datasets do not guarantee fair model outputs. Continuous testing and multiple metrics help identify and address biases.
- Example: Google’s ML model for toxicity demonstrated representational harm by labeling “I am gay” as highly toxic compared to “I am straight”.
- Fairness by Design:
- Context is crucial for accurate predictions. Gather feedback from diverse users and enable multiple user experiences.
- Example: Google Translate showed bias by translating gender-neutral Turkish terms into gendered English terms inaccurately.
By understanding and addressing these biases, ML practitioners can create more fair, ethical, and responsible AI systems. The chapter encourages the use of behavioral testing techniques to identify and mitigate biases, and highlights the importance of continuous learning and feedback.


Chapter7 Machine Learning Models in Production
Deploying a machine learning (ML) model behind a web service and related concepts:
- Checkpoints:
- Checkpoints are partial trainings of a model, similar to video game checkpoints, allowing continuation from a specific point without starting over.
- They are useful in distributed training, where multiple machines contribute to the model’s training, sharing parameters, weights, and gradients.
- Saved Models:
- Saved models are fully trained models ready for use. They can also be extended and further trained, a process known as transfer learning.
- Platforms like Hugging Face offer pre-trained models that can save significant training time, though these models should be tested for biases and fairness.
- Inference:
- Inference is the process of using a trained model to make predictions or classifications based on new data.
- An example is a text classification model for sentiment analysis, which can be tested for biases by changing input terms and observing the output.
- REST API Deployment:
- Models can be deployed behind REST APIs, allowing interaction via HTTP requests.
- Tools like Postman can be used to test these APIs, facilitating automated testing, performance testing, and load testing.
- Testing and Quality Assurance:
- Continuous testing and quality assurance are crucial throughout the ML lifecycle.
- Testing should cover various aspects, including data sets, pipelines, and model performance, to ensure holistic quality in ML and AI solutions.
- Practical Application:
- AI models are ubiquitous, found in devices and appliances, requiring thorough testing to ensure reliability and fairness.
- Collaboration among data scientists, ML engineers, software engineers, and testers is essential to apply best practices and achieve high-quality ML systems.
- Expertise and Collaboration:
- Hiring testing experts can be beneficial, as their experience and knowledge can significantly enhance the quality and performance of ML models.

